

Autoscaling means
Autoscaling is a technique that dynamically adjusts the number of computing resources allocated to your application based on its real-time demands. For instance, if your website experiences a spike in traffic at the end of every month, you may require additional web servers to manage the increased load. However, during the rest of the month, those servers remain underutilized, leading to higher cloud costs. By enabling autoscaling, the number of servers can scale up or down automatically based on the workload and user demand, optimizing both performance and cost.
In the Kubernetes era, autoscaling has become a critical component in ensuring the scalability of containerized applications. This article explores the various types of autoscalers available in Kubernetes and helps identify the most suitable autoscaler for your application needs.
There are three ways to achieve high availability in Kubernetes
- Horizontal Pod autoscaling (HPA)
- Vertical Pod Autoscaling (VPA)
- Cluster autoscaler
In a nutshell autoscaling include activity’s like :
- Adjust the number of POD : Increase or decrease the pod replicas based on the metrics (HPA)
- Adjust the resource in the POD : Increase or decrease the resource allocated to the pod(increase CPU /memory allocation) (VPA)
- Adjust the node in the cluster : Increase the number of nodes(VM) which increase overall resource allocated to the cluster (Cluster Autoscaling)
These feature make sure an application can scale up/scale down by its own base on the condition we set, normally CPU/Memory utilization, traffic to POD etc, we can also define custom parameters based on the metrics.
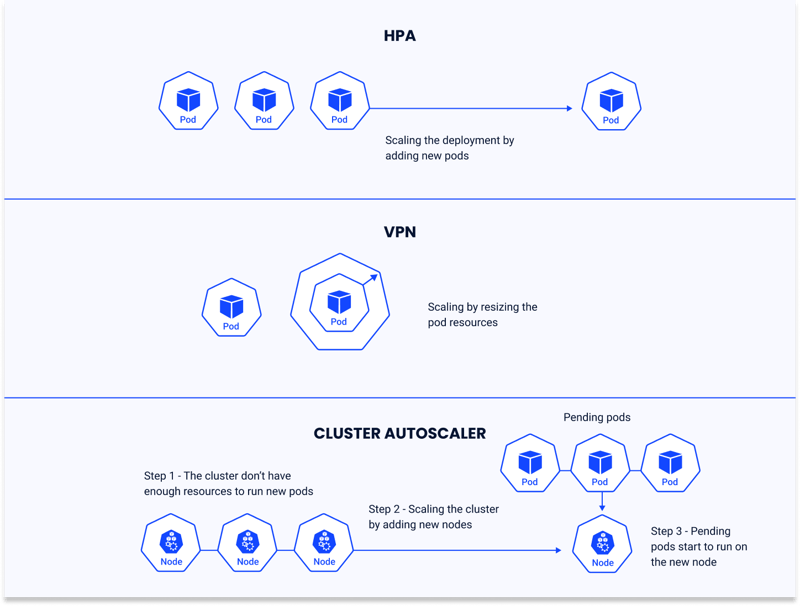
Horizontal Pod Autoscaler (HPA)
HPA is a Kubernetes feature that automatically adjusts the number of pods in a replication controller, deployment, replica set, or stateful set based on resource metrics. By default, it monitors CPU utilization, but with support for custom metrics, it can scale pods based on other application-defined metrics as well.
Setting up HPA is a simple process. It involves specifying the metrics to track, the target value for each metric, and the minimum and maximum number of pods. The HPA controller continuously monitors the defined metrics and adjusts the number of replicas to ensure the observed average resource usage aligns with the user-defined target.
How HPA Works
The HPA controller periodically checks the specified metrics, such as:
- CPU Utilization: By default, HPA monitors CPU usage to determine scaling needs.
- Memory Utilization: Memory-based scaling can also be configured.
- Custom Metrics: With custom metrics support, HPA can scale based on application-specific metrics, such as request latency, queue length, or active users.
Based on the observed metrics and the user-defined targets, HPA adjusts the number of replicas in real-time to maintain the desired resource utilization levels.
Key Components of HPA
- Metrics Server: The HPA relies on the Metrics Server to fetch resource usage data like CPU or memory utilization.
- Target Utilization: You define the target utilization (e.g., 80% CPU usage) that HPA tries to maintain.
- Scaling Constraints: HPA allows you to set a minimum and maximum number of replicas to prevent over-scaling or under-scaling.
Configuring HPA
Implementing HPA requires a few steps:
- Define the metrics to monitor (e.g., CPU or custom metrics).
- Set the target value for the metric (e.g., 70% average CPU usage).
- Specify the minimum and maximum number of replicas in the HPA configuration.
Here’s an example YAML configuration for an HPA based on CPU utilization:
Prerequisites: Metrics Server must be enabled/installed in your cluster.
Usecase 1: creating a HPA deployment file
When to Use Cluster Autoscaler
- Dynamic Workloads: Workloads with fluctuating resource demands, such as batch jobs or event-driven applications.
- Cost-Saving Initiatives: Minimizes costs by scaling down unused nodes during low-traffic periods.
- Avoiding Resource Bottlenecks: Ensures workloads are not starved of resources during traffic spikes or high-demand scenarios.
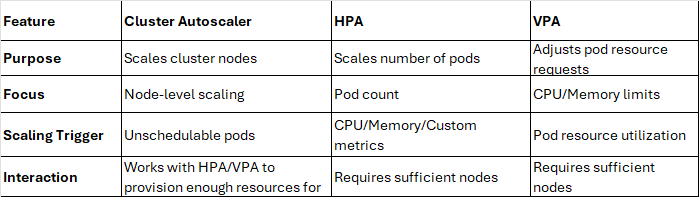
Compare Cluster Autoscaler vs Horizontal/Vertical Pod Autoscaler
Reference :
- https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
- https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
- https://kubernetes.io/docs/concepts/workloads/autoscaling/
- https://kubernetes.io/docs/tasks/configure-pod-container/resize-container-resources/
- Chatgpt

